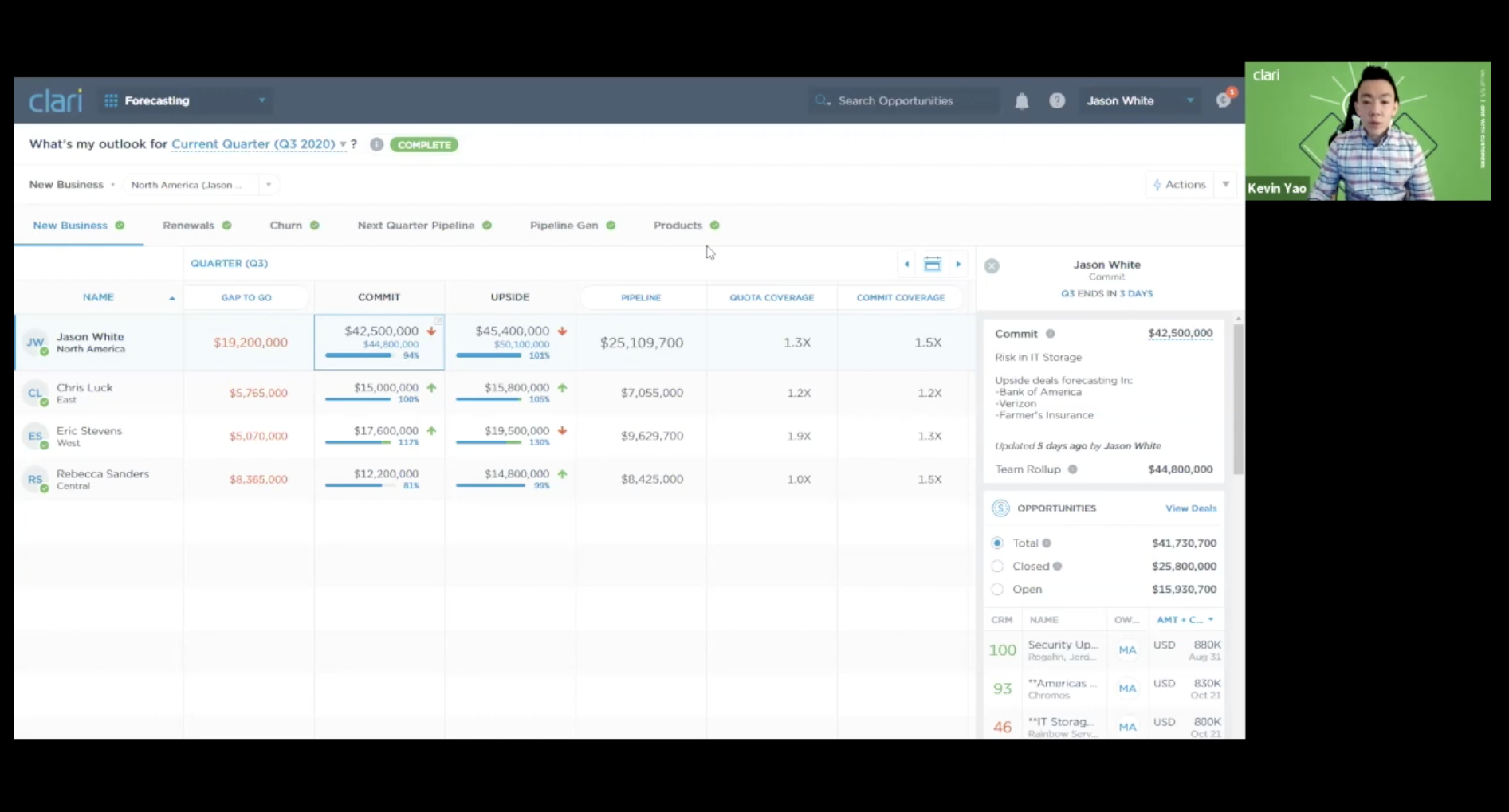
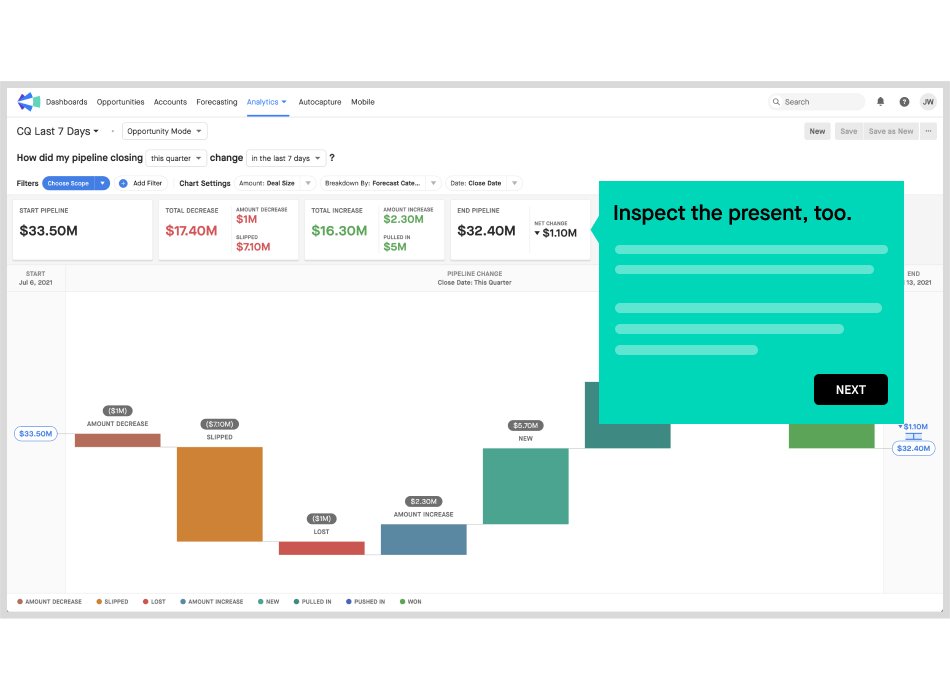
Grow revenue with confidence
Learn how to optimize Clari's platform and get inspired by leadership insights to hit targets and accelerate revenue growth.
Learn how to optimize Clari's platform and get inspired by leadership insights to hit targets and accelerate revenue growth.